Empirical Bayes method
Empirical Bayes methods are procedures for statistical inference in which the prior distribution is estimated from the data. This approach stands in contrast to standard Bayesian methods, for which the prior distribution is fixed before any data are observed. Despite this difference in perspective, empirical Bayes may be viewed as an approximation to a fully Bayesian treatment of a hierarchical model wherein the parameters at the highest level of the hierarchy are set to their most likely values, instead of being integrated out. Empirical Bayes, also known as maximum marginal likelihood,[1] represents one approach for setting hyperparameters.
Contents |
Introduction
Empirical Bayes methods can be seen as an approximation to a fully Bayesian treatment of a hierarchical Bayes model.
In, for example, a two-stage hierarchical Bayes model, observed data 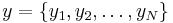 are assumed to be generated from an unobserved set of parameters
are assumed to be generated from an unobserved set of parameters 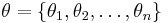 according to a probability distribution
according to a probability distribution 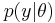 . In turn, the parameters θ can be considered samples drawn from a population characterised by hyperparameters
. In turn, the parameters θ can be considered samples drawn from a population characterised by hyperparameters 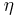 according to a probability distribution
according to a probability distribution 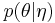 . In the hierarchical Bayes model, though not in the Empirical Bayes approximation, the hyperparameters are considered to be drawn from an unparameterized distribution
. In the hierarchical Bayes model, though not in the Empirical Bayes approximation, the hyperparameters are considered to be drawn from an unparameterized distribution 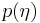 .
.
Information about a particular quantity of interest 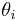 therefore comes not only from the properties of those data which directly depend on it, but also from the properties of the population of parameters
therefore comes not only from the properties of those data which directly depend on it, but also from the properties of the population of parameters 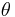 as a whole, inferred from the data as a whole, summarised by the hyperparameters
as a whole, inferred from the data as a whole, summarised by the hyperparameters 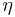 .
.
Using Bayes' theorem,
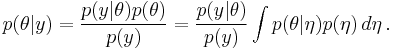
In general, this integral will not be tractable analytically and must be evaluated by numerical methods; typically stochastic approximations such as from Markov Chain Monte Carlo sampling or deterministic approximations such as quadrature.
Alternatively, the expression can be written as
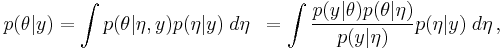
and we can expand
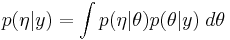
These suggest an iterative scheme, qualitatively similar in structure to a Gibbs sampler, to evolve successively improved approximations to 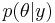 and
and 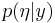 . First, calculate an initial approximation to ignoring the
. First, calculate an initial approximation to ignoring the 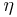 dependence completely; then calculate an approximation to based upon the initial approximate distribution of ; then use this to update the approximation for ; then update ; and so on.
dependence completely; then calculate an approximation to based upon the initial approximate distribution of ; then use this to update the approximation for ; then update ; and so on.
When the true distribution is sharply peaked, the integral determining may be not much changed by replacing the probability distribution over with a point estimate 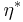 representing the distribution's peak (or, alternatively, its mean),
representing the distribution's peak (or, alternatively, its mean),
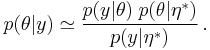
With this approximation, the above iterative scheme becomes the EM algorithm.
"Empirical Bayes" as a label can cover a wide variety of methods, but most can be regarded as an early truncation of either the above scheme or something quite like it. Point estimates, rather than the whole distribution, are typically used for the parameter(s) ; the estimates for are typically made from the first approximation to without subsequent refinement; these estimates for are usually made without considering an appropriate prior distribution for .
Point estimation
Robbins method (1956): non-parametric empirical Bayes (NPEB)
We consider a case of compound sampling, where probability for each 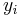 (conditional on
(conditional on 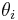 ) is specified by a Poisson distribution,
) is specified by a Poisson distribution,
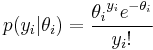
while the prior is unspecified except that it is also i.i.d. (call it 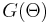 ). Compound sampling arises in a variety of statistical estimation problems, such as accident rates and clinical trials. We simply seek a point prediction of given all the observed data. Because the prior is unspecified, we seek to do this without knowledge of G (see Carlin and Louis, Sec. 3.2 and Appendix B).
). Compound sampling arises in a variety of statistical estimation problems, such as accident rates and clinical trials. We simply seek a point prediction of given all the observed data. Because the prior is unspecified, we seek to do this without knowledge of G (see Carlin and Louis, Sec. 3.2 and Appendix B).
Under squared error loss (SEL), the conditional expectation E(θi | Yi = yi) is a reasonable quantity to use for prediction. For the Poisson compound sampling model, this quantity is
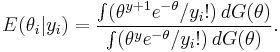
This can be simplified by multiplying the expression by 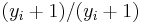 , yielding
, yielding
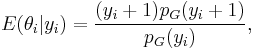
where pG is the marginal distribution obtained by integrating out θ over G.
To take advantage of this, Robbins (1955) suggested estimating the marginals with their empirical frequencies, yielding the fully non-parametric estimate as:
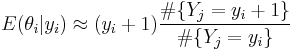
(see also Good–Turing frequency estimation).
Example: Accident rates
Suppose each customer of an insurance company has an "accident rate" Θ and is insured against accidents; the probability distribution of 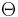 is the underlying distribution, and is unknown. The number of accidents suffered by each customer in a specified time period has a Poisson distribution with expected value equal to the particular customer's accident rate. The actual number of accidents experienced by a customer is the observable quantity. A crude way to estimate the underlying probability distribution of the accident rate Θ is to estimate the proportion of members of the whole population suffering 0, 1, 2, 3, ... accidents during the specified time period as the corresponding proportion in the observed random sample. Having done so, it is then desired to predict the accident rate of each customer in the sample. As above, one may use the conditional expected value of the accident rate Θ given the observed number of accidents during the baseline period. Thus, if a customer suffers six accidents during the baseline period, that customer's estimated accident rate is 7 × [the proportion of the sample who suffered 7 accidents] / [the proportion of the sample who suffered 6 accidents]. Note that if the proportion of people suffering k accidents is a decreasing function of k, the customer's predicted accident rate is lower than their observed number of accidents. This shrinkage effect is typical of Empirical Bayes analyses.
is the underlying distribution, and is unknown. The number of accidents suffered by each customer in a specified time period has a Poisson distribution with expected value equal to the particular customer's accident rate. The actual number of accidents experienced by a customer is the observable quantity. A crude way to estimate the underlying probability distribution of the accident rate Θ is to estimate the proportion of members of the whole population suffering 0, 1, 2, 3, ... accidents during the specified time period as the corresponding proportion in the observed random sample. Having done so, it is then desired to predict the accident rate of each customer in the sample. As above, one may use the conditional expected value of the accident rate Θ given the observed number of accidents during the baseline period. Thus, if a customer suffers six accidents during the baseline period, that customer's estimated accident rate is 7 × [the proportion of the sample who suffered 7 accidents] / [the proportion of the sample who suffered 6 accidents]. Note that if the proportion of people suffering k accidents is a decreasing function of k, the customer's predicted accident rate is lower than their observed number of accidents. This shrinkage effect is typical of Empirical Bayes analyses.
Parametric empirical Bayes
If the likelihood and its prior take on simple parametric forms (such as 1- or 2-dimensional likelihood functions with simple conjugate priors), then the empirical Bayes problem is only to estimate the marginal 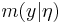 and the hyperparameters using the complete set of empirical measurements. For example, one common approach, called parametric Empirical Bayes point estimation, is to approximate the marginal using the maximum likelihood estimate (MLE), or a Moments expansion, which allows one to express the hyperparameters in terms of the empirical mean and variance. This simplified marginal allows one to plug in the empirical averages into a point estimate for the prior
and the hyperparameters using the complete set of empirical measurements. For example, one common approach, called parametric Empirical Bayes point estimation, is to approximate the marginal using the maximum likelihood estimate (MLE), or a Moments expansion, which allows one to express the hyperparameters in terms of the empirical mean and variance. This simplified marginal allows one to plug in the empirical averages into a point estimate for the prior 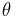 . The resulting equation for the prior is greatly simplified, as shown below.
. The resulting equation for the prior is greatly simplified, as shown below.
There are several common Parametric Empirical Bayes models, including the Poisson-Gamma model (below), the Beta-binomial model, the Gaussian-Gaussian model, the multinomial-Dirichlet (or multivariate Pólya) model, as well specific models for Bayesian linear regression (see below) and Bayesian multivariate linear regression. More advanced approaches include hierarchical Bayes models and Bayesian mixture models.
Poisson-Gamma model
For example, in the example above, let the likelihood be a Poisson distribution, and let the prior now be specified by the conjugate prior, which is a Gamma distribution (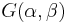 ) (where
) (where 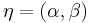 ):
):
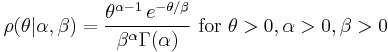
It is straightforward to show the posterior is also a Gamma distribution. Write
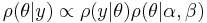
where we have omitted the marginal since it does not depend explicitly on . Expanding terms which do depend on gives the posterior as:
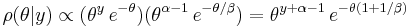
So we see that the posterior density is also a Gamma distribution 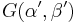 , where
, where 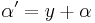 , and
, and 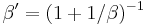 . Also notice that the marginal is simply the integral of the posterior over all , which turns out to be a negative binomial distribution.
. Also notice that the marginal is simply the integral of the posterior over all , which turns out to be a negative binomial distribution.
To apply empirical Bayes, we will approximate the marginal using the maximum likelihood estimate (MLE). But since the posterior is a Gamma distribution, the MLE of the marginal turns out to be just the mean of the posterior, which is the point estimate 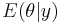 we need. Recalling that the mean
we need. Recalling that the mean 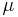 of a Gamma distribution is simply
of a Gamma distribution is simply 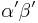 , we have
, we have
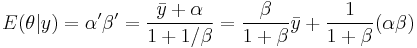
To obtain the values of  and
and 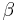 , empirical Bayes prescribes estimating mean
, empirical Bayes prescribes estimating mean 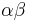 and variance
and variance 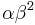 using the complete set of empirical data.
using the complete set of empirical data.
The resulting point estimate is therefore like a weighted average of the sample mean 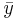 and the prior mean
and the prior mean 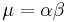 . This turns out to be a general feature of empirical Bayes; the point estimates for the prior (i.e. mean) will look like a weighted averages of the sample estimate and the prior estimate (likewise for estimates of the variance).
. This turns out to be a general feature of empirical Bayes; the point estimates for the prior (i.e. mean) will look like a weighted averages of the sample estimate and the prior estimate (likewise for estimates of the variance).
See also
- Bayes estimator
- Bayes' theorem
- Bayesian brain
- Bayesian probability
- Best linear unbiased prediction
- Conditional probability
- Monty Hall problem
- Posterior probability
- Bayesian coding hypothesis
- Robbins lemma
References
- ^ C.M. Bishop (2005). Neural networks for pattern recognition. Oxford University Press
- Robbins, Herbert (1956). "An Empirical Bayes Approach to Statistics". Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics: 157–163. MR0084919. http://projecteuclid.org/euclid.bsmsp/1200501653. Retrieved 2008-03-15.
- Carlin, Bradley P.; Louis, Thomas A. (2000). Bayes and Empirical Bayes Methods for Data Analysis (2nd ed.). Chapman & Hall/CRC. ISBN 1584881704.
- Peter E. Rossi, Greg M. Allenby, and Robert McCulloch, Bayesian Statistics and Marketing, John Wiley & Sons, Ltd, 2006
- Casella, George (May 1985). "An Introduction to Empirical Bayes Data Analysis". American Statistician (American Statistical Association) 39 (2): 83–87. doi:10.2307/2682801. JSTOR 2682801. MR0789118.
- Nikulin, Mikhail (1987). "Bernstein's regularity conditions in a problem of empirical Bayesian approach". Journal of Soviet Mathematics, 36 (5): 596–600.. doi:10.1007/BF01093293.